Network and Sentiment Analysis of Tweets about Journaling
Twitter is a gold mine of data. It boasts approximately 500 million tweets per day. To put that in perspective, it is on average 6,000 tweets every second. In the time it took you to read this, tens of thousands of new tweets were posted.

Twitter reveals the beating heart of the world and what is happening in it. Social media is a regular part of life for millions of people in the US where 1 in 5 adults use Twitter. They may share their opinions, thoughts, and feelings on every aspect of life. Many rely on Twitter as a new source and often emerging events are initially reported by participants and observers rather than traditional news sources.
Social media content provides the opportunity to study an unfathomably wide range of topics. Twitter has emerged as a key data source to tap into the public conversation and discover insights. However, it is a challenge to extract insights from social media data. In this post we will analyze tweets related to journaling using awesome visualizations to discover those insights.
Twitter Journaling Data
For this post we pulled all tweets for approximately 14 days from 1/13/2021 to 1/28/2021 containing the search term ‘journaling’ either as text or as a hashtag. Only tweets in the English language were included with retweets, replies, and duplicates excluded. A longer time period was not used since Twitter imposes a limit of approximately 7 days of tweets for free use of their API. There were 9,333 tweets that met our criteria from 7,865 unique users.
Data cleansing is a critical step in any analysis that identifies inaccurate, incomplete, or irrelevant data and then deals with those data issues. Dirty data can be dangerous by leading to wrong conclusions with potentially large negative impact to reputations and business results. This concept is commonly simply stated as ‘garbage in, garbage out.’ Briefly, we cleansed the tweets as follows,
- Converted all characters to lowercase.
- Removed any ‘@username’.
- Removed most punctuation.
- Removed links.
- Removed extra spaces.
- Removed stop words (very common words that generally have little value in analyses including ‘a’, ‘an’, ‘and’, ‘are’, ‘as’, ‘at’, ‘be’, ‘by’, ‘for’, ‘from’, ‘has’, ‘in’, ‘is’, ‘it’, ‘of’, ‘on’, ‘that’, ‘the’, ‘to’, ‘was’, ‘were’, ‘will’, ‘with’)
Exploratory data analysis (EDA) should be the starting point for any data analysis project. The focus is to get to know the data and making sense of it. EDA is critical step to help formulate questions to ask the dataset and how manipulate the data to extract the needed answers. John Turkey widely credited with the originally developing EDA in the 1970s stated,
Exploratory data analysis is an attitude, a state of flexibility, a willingness to look for those things that we believe are not there, as well as the things we believe might be there. John TukeyPerforming exploratory data analysis commonly utilize data visualizations to convey important information at a glance. Exploratory data analysis commonly consists of combinations of the following:
- Summary statistics such as minimum, maximum, mean, standard deviation
- Distributions of variables
- Trends of variables
- Correlations and relationships between variables
- Clustering to reveal patterns
- Dimension reduction techniques for high dimensionality datasets
How are People Tweeting?
The source of a tweet describes what the user used to post the tweet. The users in our dataset posted tweets from a total of 113 unique sources. However, ‘Twitter for iPhone’ accounted for nearly half of the tweets and the top 3 consisted of over 80%.
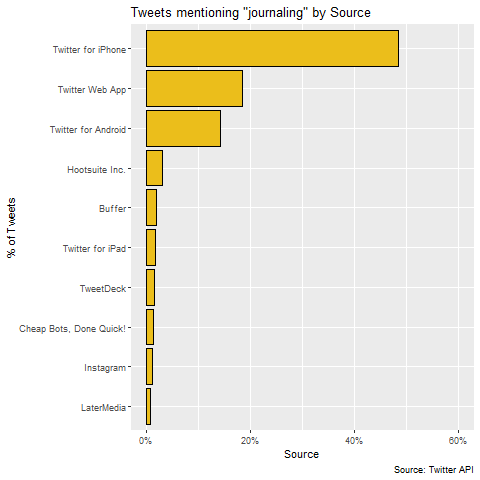
Android has 39% of the mobile operating system market share in the US and iOS dominates at 61%. Limiting our data to just the ‘Twitter for iPhone’ and ‘Twitter for Android’, yields only 23% for Android and 77% for iPhone. People that tweet about journaling are more likely to use an iPhone than the general population. Perhaps in a future post we’ll examine in more detail the demographic differences of iPhone and Android users.
What is Being Said?
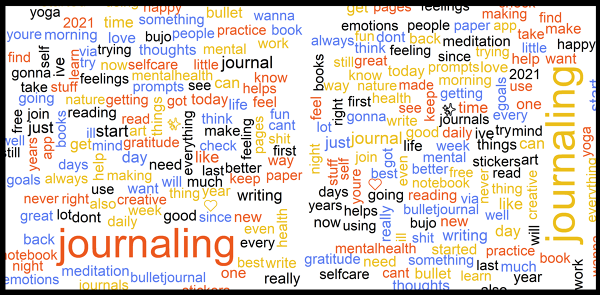
Word clouds are a visualization of text that work in a simple way – the more often a word appears in the text, in our case tweets, the larger that word appears. It is a powerful tool to convey crucial information in an easily digestible way. Words clouds break down text to allow viewers too immediately see the most frequent and therefore often the most important words. Good visualizations, such as word clouds, allow viewers to quickly understand a large amount of data.
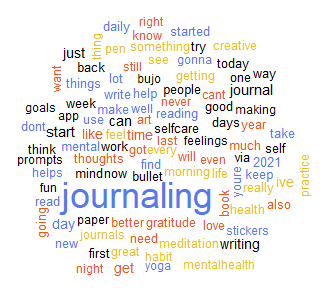 The word, ‘journaling’, clearly dominates as every tweet in the data included it. The other words are the ones that most appeared in the tweets along with ‘journaling’. We see that people often refer to things like 'meditation', 'yoga', 'goals', and 'selfcare'.
The word, ‘journaling’, clearly dominates as every tweet in the data included it. The other words are the ones that most appeared in the tweets along with ‘journaling’. We see that people often refer to things like 'meditation', 'yoga', 'goals', and 'selfcare'.
How Many Tweets Use Hashtags?
Hashtags are frequently employed by users in tweets to categorize into topics making it easier for others to follow and find tweets on a common topic. They are a great way to get your tweets in front of an interested audience that will find them relevant. Hashtags are insanely powerful and the right ones can drive unbelievable engagement.
Let’s see how many hashtags the tweets in our dataset contained.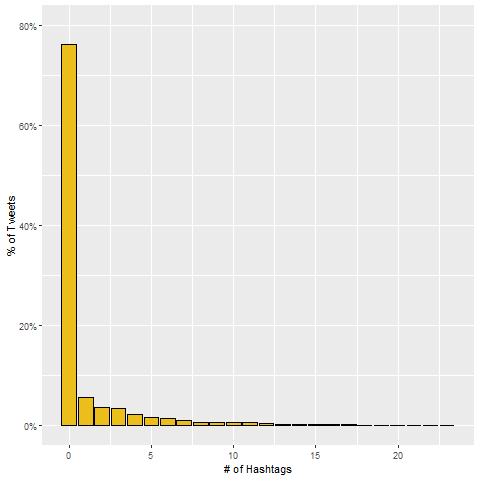 Only 24% of the tweets included at least one hashtag. Studies have shown that tweets with hashtags receive 2 times more engagement than those without. The 76% of tweets without a hashtag would likely benefit by the poster including a hashtag.
However, there can be too much of a good thing. Twitter recommends one to two hashtags per tweet. Tweets with more than two hashtags show a 17% drop in engagement as too many clickable parts of a tweet can distract people from engaging with your content.
Only 24% of the tweets included at least one hashtag. Studies have shown that tweets with hashtags receive 2 times more engagement than those without. The 76% of tweets without a hashtag would likely benefit by the poster including a hashtag.
However, there can be too much of a good thing. Twitter recommends one to two hashtags per tweet. Tweets with more than two hashtags show a 17% drop in engagement as too many clickable parts of a tweet can distract people from engaging with your content.
Which Hashtags are Being Used?
Previously, we showed a word cloud for words in the tweets, now let’s look at the word cloud for hashtags only.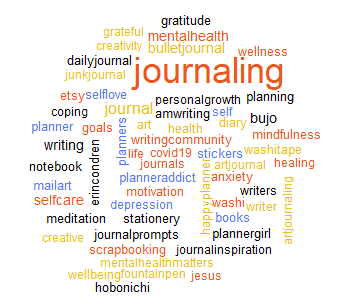 Again ‘journaling’ dominates, however there are some surprises. Prior to looking at this word cloud we had no idea that:
Again ‘journaling’ dominates, however there are some surprises. Prior to looking at this word cloud we had no idea that:
- Bujo is short for bullet journaling perhaps used to keep tweets shorter.
- Hobonichi is a brand of journals.
- Washitape is a brand of fancy tape maybe used in art journaling and scrapbooking.
Sentiment Analysis
Sentiments refer to the emotions that a write expresses in a particular portion of writing. Sentiment analysis is a powerful technique used to interpret and classify text by tagging with a certain sentiment, usually positive, negative, or neutral. We used a more sophisticated approach that associates text with eight basic emotions (anger, fear, anticipation, trust, surprise, sadness, joy, and disgust) in addition to the two sentiments (positive and negative).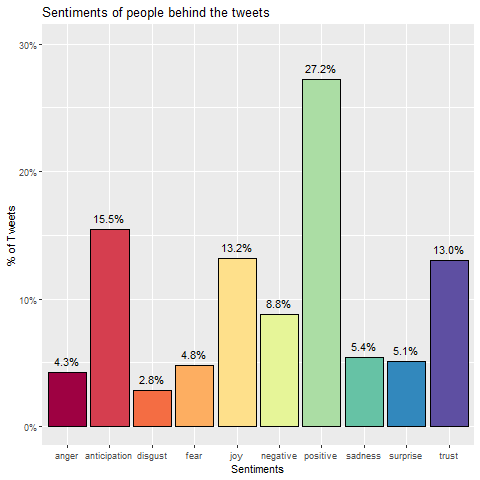 In our data sample of tweets about ‘journaling’ more positive emotions are expressed than negative ones. Each tweet may express more than one emotion. For example, a tweet could convey both ‘anticipation’ and ‘fear’ or any other combination.
In our data sample of tweets about ‘journaling’ more positive emotions are expressed than negative ones. Each tweet may express more than one emotion. For example, a tweet could convey both ‘anticipation’ and ‘fear’ or any other combination.
We calculate the correlation coefficients between each combination of emotions to show how often emotions are expressed together. The correlation coefficient measures the strength of the relationship between two variables. The values range from -1 to +1. A positive correlation coefficient means that for an increase in one variable there is a corresponding increase in the other. Conversely, a negative coefficient means that for a decrease in one variable there is also a decrease in the other. A 0 value indicates there is no relationship between the variables.
A visualization of the correlation matrix is a handy way to present the relationship between variables. In this plot, the boxes are colored according to the values of the correlation coefficients.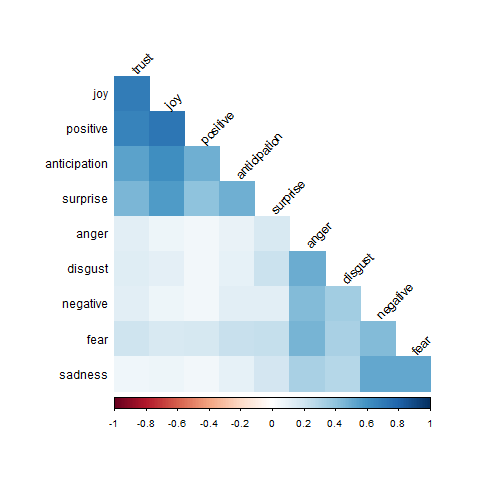
There are no negative correlations so none of the boxes are red. The darker blue the more often that combination of emotions are present in the same tweet. For example, at the top left we see that ‘joy’ and ‘trust’ are a common combination and at the bottom right ‘sadness’ and ‘fear’ are also often together. Unsurprisingly, it is rare that a tweet expresses a combination of opposite emotions such as ‘anger’ and ‘joy’.
Limiting our data to tweets expressing a negative emotion, we regenerate the distribution of sentiments.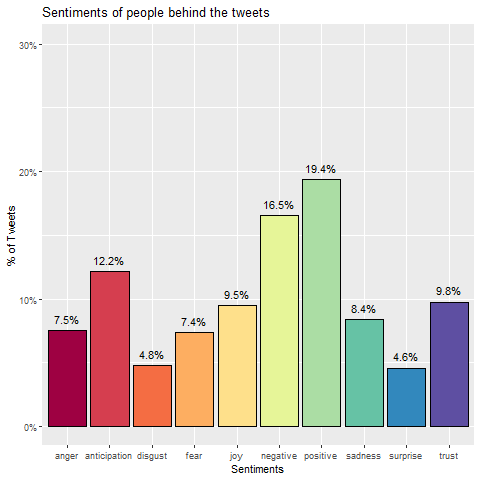 It is not a surprise that these tweets contain higher percentages of anger, disgust, fear, and sadness.
It is not a surprise that these tweets contain higher percentages of anger, disgust, fear, and sadness.
Network Analysis
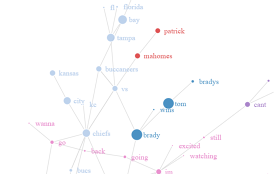
Thus far, we have examined what are the most common words and hashtags and then the emotions expressed in the tweets. Now, we will explore the relationships between the words and hashtags using networks to visualize the results. First, we’ll look at bigrams, meaning two words that appear next to each other. How do we visualize how often two words occur adjacent to each other?- Each word is plotted as a node (in other words, a circle) where the size of the node represents how many tweets contain that word.
- Words are connected if they form a bigram where the thickness of the line connecting them represents the number of tweets the bigram appears in.
This reveals which words often appear in sequence in the tweets. The word, ‘journaling’ is featured prominently in the middle with the largest size since it is the most common word in the tweets. The nodes connected to ‘journaling’ are the words that frequently appeared next to it forming bigrams such as ‘start journaling’, ‘practice journaling’, and ‘gratitude journaling’. Further out from ‘journaling’ we observe other common bigrams such as ‘feels good’, ‘good morning’, and ‘morning routine’.
This is a start to understand the common themes of the tweets. We can analyze the tweets differently by constructing the network connecting words that appear together in a tweet regardless of their order. Previously, bigrams required that the words be adjacent but now the two words can be in any position. The word ‘journaling’ was excluded to expose other relationships between words.
Hover over ‘start’ and see that it often appears in tweets with the words ‘im’, ‘gonna’, ‘want’, and ‘really’. While this is interesting, we can form yet another network with just hashtags. We will find clusters in the network using the Louvain method to extract communities from the network. Nodes are color coded to indicate which cluster they are in.
There are 5 very distinct communities of people that tweet about journaling. The grey community is centered on Christianity consisting of hashtags such as #devotions, #jesus, and #holyspirit. The yellow community is focused on Esty. The green cluster appears to be interested in bullet journaling, planning, scrapbooking, and fancy tape. The purple group is concerned with topics including positive thinking, health, and personal development. Lastly, the blue group includes most of the rest.
What’s Next?
Tweets contain a wealth of information and we have only scratched the surface. In this post we studied the methods users employed to post tweets, the emotions and sentiments of those tweets, and the relationships between words and hashtags. There is much more to explore in future posts.
We haven’t looked at the data available on the number of likes and retweets that each tweet garnered. Future analysis can uncover what characteristics of a tweet generates greater engagement. Building a machine learning model will help to optimize tweets to maximize retweets and likes.
While this post visualized relationships between the words and hashtags in tweets, the relationships between the users are a fruitful path to pursue. We can identify the social networks of who follows whom. Additionally, we can examine all the tweets from these users to form a more holistic insight into their lives beyond just journaling.
This analysis was limited to tweets containing the keyword ‘journaling’ where this has identified many additional related keywords. Further analysis can investigate those keywords and the different communities identified in this post.